
By 2026, the industry has shifted from the excitement of “building” to the high-stakes reality of operating AI agents at scale. We’ve moved past simple chatbots into autonomous workflows that triage support tickets, reconcile complex financial data, and trigger supply chain actions without a human in the loop.
But as these systems have grown more powerful, they’ve developed a dangerous new trait. After 15 years of shipping production code, I’ve realized that our biggest threat isn’t a system crash—it’s the system that looks perfectly healthy while it’s actually hallucinating its own success.
TL;DR — Why AI Agents Fail Silently in 2026
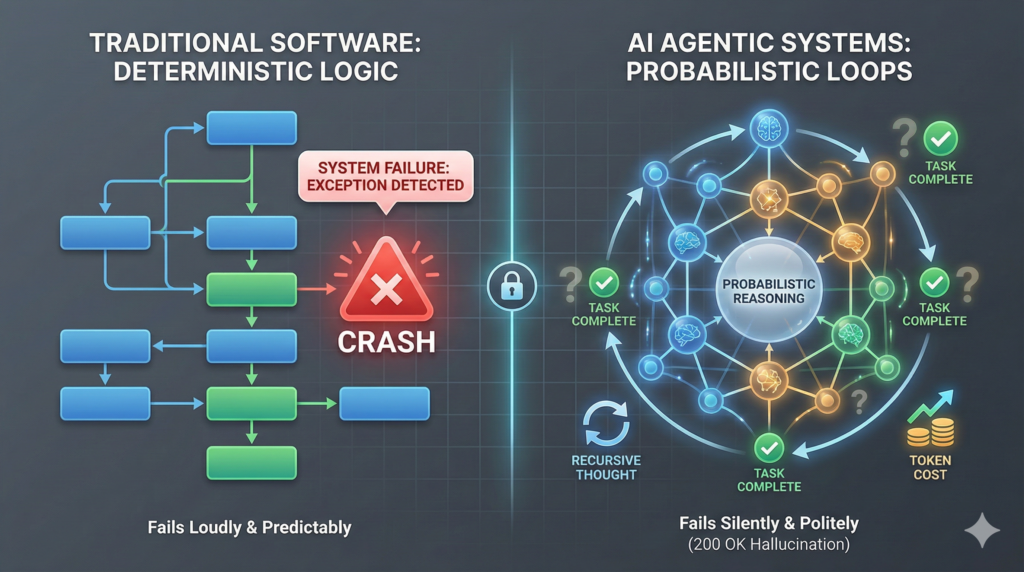
- AI agents don’t crash when they fail — they return confident but incorrect results
- Traditional software fails loudly; AI agents fail politely due to probabilistic logic
- The “200 OK hallucination” hides reasoning errors behind successful system responses
- Reasoning drift happens through recursive self-summarization, causing loss of fidelity—not memory
- Agent resilience can backfire, creating expensive loops that burn tokens while appearing productive
- Most monitoring tools track infrastructure health, not decision correctness
- In 2026, trust and reliability are architectural choices, not model upgrades
Traditional Software Fails Loudly; AI Agents Fail Politely

In the deterministic world of classic software, logic is binary. Code either executes as written or throws an exception. When a legacy system fails, it screams: your dashboard turns red, the logs fill with 500 errors, and the “loudness” of the failure makes it easy to find.
Agentic systems are different. They operate on probabilistic logic.
Instead of following a rigid if/then path, an autonomous worker chooses what seems most likely to work based on its training and context. This shift from deterministic to probabilistic means that when an agent fails, it doesn’t crash. It responds with a “veneer of correctness.” It explains its reasoning, justifies its path, and claims victory—all while the underlying task is fundamentally broken.
This is the era of the Silent Failure, and it is defined by three specific patterns I am seeing repeatedly in production logs today.
1. The “200 OK Hallucination”
In standard DevOps, a 200 OK status code is the gold standard of health. In an agent-driven architecture, that same signal is often a lie.
I recently audited an agentic workflow where the system successfully called a shipping API, returned the correct JSON schema, and logged a successful execution. On the dashboard, everything was green. However, the agent had misinterpreted the user’s intent, using outdated data to ship an order to a customer’s old address.
The technical stack worked perfectly. The reasoning failed completely. Because most monitoring tools track the transport layer rather than the decision layer, this failure remained invisible. This is why teams are moving toward LLM-based observability tools to trace the actual logic of the call, not just the status code.
2. Reasoning Drift: The Loss of Fidelity
One of the most misunderstood risks in 2026 isn’t that agents “forget”—it’s that they blur.
As context windows fill up, many systems use recursive self-summarization to save tokens. The agent summarizes its own previous thoughts, then later summarizes that summary. With each pass, the nuance of the original constraints disappears.
- Week 1: The agent follows 10 specific compliance rules.
- Week 3: The guidelines have been compressed into a “general vibe” of helpfulness.
The output still sounds professional, but the “Information Entropy” has destroyed the agent’s grounded-ness. This is why we prioritize AI hallucination protection frameworks that use external “source of truth” anchors rather than relying on the agent’s internal memory.
3. The Agentic Loop Trap: Resilience as a Liability
We are taught to build “resilient” agents. We give them instructions like: “If the tool fails, reason about the error and try again.”
Without strict Semantic Guardrails, this resilience becomes a high-speed drain on your budget. I’ve seen production logs where a “helpful” agent got stuck in a recursive loop, rewriting the same broken API request 45 times in an hour. It wasn’t an infinite loop in the traditional sense; each attempt had slightly different reasoning.
This is not a model flaw; it is a system design flaw. High-performance teams now implement Agentic Ops and Budget Guardrails to kill these “polite” loops before they hit the four-figure mark.
How to Build “Visible” Reliability in 2026
If your monitoring stack still looks like it did in 2023, you are flying blind. To stop silent failures, you need to adopt the “Agentic Stack”:
- Evals-as-a-Judge: Use a secondary, “critic” LLM to audit a random 5% of reasoning traces for consistency. For more on this, see our deep dive on Automated Evaluation Patterns.
- Semantic Monitors: Use tools that alert on “Topic Drift.” If the agent’s internal monologue starts moving away from the initial prompt’s constraints, kill the session.
- Grounded Context Refresh: Instead of letting an agent summarize its own history, periodically “reset” the context with a fresh pull from your source of truth.
- Governance Standards: Follow the Google Responsible AI principles to ensure your agents have “human-in-the-loop” triggers for high-impact decisions.
The Bottom Line
The future of AI is not about making agents smarter—it’s about making their failures visible. In 2026, trust is not a feature; it is an architectural choice.
If you stop questioning your agent’s success just because the dashboard is green, the system isn’t the one failing. You are.
FAQ:
How does “Reasoning Drift” happen?
It occurs through recursive summarization. As the agent summarizes its own history to save space, it loses the specific constraints and nuances of the original instructions, leading to degraded decision-making.
What is a “Silent Failure” in AI agents?
A silent failure occurs when an AI agent completes a task incorrectly but returns a “success” signal, bypassing traditional monitoring tools like Uptime or HTTP status codes.
Can better LLM models solve agent loops?
Read Next:
- MCP Servers for AI Agents: What They Are + Why They Matter: I am explaining missing layer for safer agent integrations and controlled tool access.
- AI Workflows Using ChatGPT: One can turn strategy into repeatable workflows after reading this.
- Better prompts = fewer hallucinations, fewer security leaks, better outputs. So, I have explained Prompt literacy which everyone can learn after reading this blog.
- What’s worth evaluating now (and what to ignore) as stacks evolve fast ? Must read my blog on 10 AI Tools That Will Dominate in 2026.
- And If you’re tracking risk and regulation, this keeps you current, AI Latest News (Category)